projects
2024
2024
-
 PokeFlex: Towards a Real-World Dataset of Deformable Objects for Robotic ManipulationJan Obrist, Miguel Zamora, Hehui Zheng, Juan Zarate, and 2 more authorsExtended abstract. ICRA40, 2024
PokeFlex: Towards a Real-World Dataset of Deformable Objects for Robotic ManipulationJan Obrist, Miguel Zamora, Hehui Zheng, Juan Zarate, and 2 more authorsExtended abstract. ICRA40, 2024Advancing robotic manipulation of deformable objects can enable automation of repetitive tasks across multiple industries, from food processing to textiles and healthcare. Yet robots struggle with the high dimensionality of deformable objects and their complex dynamics. While data-driven methods have shown potential for solving manipulation tasks, their application in the domain of deformable objects has been constrained by the lack of data. To address this, we propose PokeFlex, a pilot dataset featuring real-world 3D mesh data of actively deformed objects, together with the corresponding forces applied by a robotic arm, using a simple poking strategy. Deformations are captured with a professional volumetric capture system that allows for complete 360-degree reconstruction. The PokeFlex dataset consists of five deformable objects with varying stiffness and shapes. Additionally, we leverage the PokeFlex dataset to train a vision model for online 3D mesh reconstruction from a single image and a template mesh. We refer readers to the supplementary material for demos and examples of our dataset.
-
 TAPAS: A Dataset for Task Assignment and Planning for Multi Agent SystemsMiguel Zamora, Valentin N. Hartmann, and Stelian CorosWorkshop on Data Generation for Robotics at Robotics, Science and Systems ’24, 2024
TAPAS: A Dataset for Task Assignment and Planning for Multi Agent SystemsMiguel Zamora, Valentin N. Hartmann, and Stelian CorosWorkshop on Data Generation for Robotics at Robotics, Science and Systems ’24, 2024Obtaining real world data for robotics tasks is harder than for other modalities such as vision and text. The data that is currently available for robot learning is mostly set in static scenes, and deals with a single robot only. Dealing with multiple robots comes with additional difficulties compared to single robot settings: the motion planning for multiple agents needs to take into account the movement of the other robots, and task planning needs to consider to which robot a task is assigned to, in addition to when a task should be done. In this work, we present TAPAS, a simulated dataset containing task and motion plans for multiple robots acting asynchronously in the same workspace and modifying the same environment. We consider prehensile manipulation in this dataset, and focus on various pick and place tasks. We demonstrate that training using this data for predicting makespan of a task sequence enables speeding up finding low makespan sequences by ranking sequences before computing the full motion plan.
-
 Deep Compliant Control for Legged RobotsAdrian Hartmann, Dongho Kang, Fatemeh Zargarbashi, Miguel Zamora, and 1 more authorIn 2024 IEEE International Conference on Robotics and Automation (ICRA), 2024
Deep Compliant Control for Legged RobotsAdrian Hartmann, Dongho Kang, Fatemeh Zargarbashi, Miguel Zamora, and 1 more authorIn 2024 IEEE International Conference on Robotics and Automation (ICRA), 2024Control policies trained using deep reinforcement learning often generate stiff, high-frequency motions in response to unexpected disturbances. To promote more natural and compliant balance recovery strategies, we propose a simple modification to the typical reinforcement learning training process. Our key insight is that stiff responses to perturbations are due to an agent’s incentive to maximize task rewards at all times, even as perturbations are being applied. As an alternative, we introduce an explicit recovery stage where tracking rewards are given irrespective of the motions generated by the control policy. This allows agents a chance to gradually recover from disturbances before attempting to carry out their main tasks. Through an in-depth analysis, we highlight both the compliant nature of the resulting control policies, as well as the benefits that compliance brings to legged locomotion. In our simulation and hardware experiments, the compliant policy achieves more robust, energy-efficient, and safe interactions with the environment.
@inproceedings{hartmann2024deep, author = {Hartmann, Adrian and Kang, Dongho and Zargarbashi, Fatemeh and Zamora, Miguel and Coros, Stelian}, booktitle = {2024 IEEE International Conference on Robotics and Automation (ICRA)}, title = {Deep Compliant Control for Legged Robots}, year = {2024}, pages = {11421-11427}, keywords = {Training;Legged locomotion;Uncertainty;Tracking;Perturbation methods;Process control;Energy efficiency}, doi = {10.1109/ICRA57147.2024.10611209}, } -
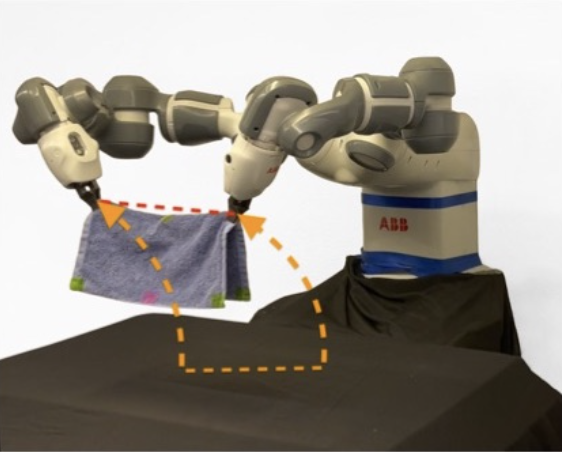 TRTM: Template-based Reconstruction and Target-oriented Manipulation of Crumpled ClothsWenbo Wang, Gen Li, Miguel Zamora, and Stelian Coros2024 IEEE International Conference on Robotics and Automation (ICRA), 2024
TRTM: Template-based Reconstruction and Target-oriented Manipulation of Crumpled ClothsWenbo Wang, Gen Li, Miguel Zamora, and Stelian Coros2024 IEEE International Conference on Robotics and Automation (ICRA), 2024Precise reconstruction and manipulation of the crumpled cloths is challenging due to the high dimensionality of cloth models, as well as the limited observation at self-occluded regions. We leverage the recent progress in the field of single-view reconstruction to template-based reconstruct the crumpled cloths from their top-view depth observations only, with our proposed sim-real registration protocols. In contrast to previous implicit cloth representations, our reconstruction mesh explicitly describes the positions and visibilities of the entire cloth mesh vertices, enabling more efficient dual-arm and single-arm target-oriented manipulations. Experiments demonstrate that our TRTM system can be applied to daily cloths that have similar topologies as our template mesh, but with different shapes, sizes, patterns, and physical properties. Videos, datasets, pre-trained models, and code can be downloaded from our project website: https://wenbwa.github.io/TRTM/.
2023
2023
-
 RL+ Model-based Control: Using On-demand Optimal Control to Learn Versatile Legged LocomotionDongho Kang, Jin Cheng, Miguel Zamora, Fatemeh Zargarbashi, and 1 more authorIEEE Robotics and Automation Letters (RA-L), 2023
RL+ Model-based Control: Using On-demand Optimal Control to Learn Versatile Legged LocomotionDongho Kang, Jin Cheng, Miguel Zamora, Fatemeh Zargarbashi, and 1 more authorIEEE Robotics and Automation Letters (RA-L), 2023This letter presents a versatile control method for dynamic and robust legged locomotion that integrates model-based optimal control with reinforcement learning (RL). Our approach involves training an RL policy to imitate reference motions generated on-demand through solving a finite-horizon optimal control problem. This integration enables the policy to leverage human expertise in generating motions to imitate while also allowing it to generalize to more complex scenarios that require a more complex dynamics model. Our method successfully learns control policies capable of generating diverse quadrupedal gait patterns and maintaining stability against unexpected external perturbations in both simulation and hardware experiments. Furthermore, we demonstrate the adaptability of our method to more complex locomotion tasks on uneven terrain without the need for excessive reward shaping or hyperparameter tuning.
-
 Embracing Safe Contacts with Contact-aware Planning and ControlZhaoting Li, Miguel Zamora, Hehui Zheng, and Stelian CorosRSS 2023. Workshop: Experiment-oriented Locomotion and Manipulation Research, 2023
Embracing Safe Contacts with Contact-aware Planning and ControlZhaoting Li, Miguel Zamora, Hehui Zheng, and Stelian CorosRSS 2023. Workshop: Experiment-oriented Locomotion and Manipulation Research, 2023Unlike human beings that can employ the entire surface of their limbs as a means to establish contact with their environment, robots are typically programmed to interact with their environments via their end-effectors, in a collision-free fashion, to avoid damaging their environment. In a departure from such a traditional approach, this work presents a contact-aware controller for reference tracking that maintains interaction forces on the surface of the robot below a safety threshold in the presence of both rigid and soft contacts. Furthermore, we leveraged the proposed controller to extend the BiTRRT sample-based planning method to be contact-aware, using a simplified contact model. The effectiveness of our framework is demonstrated in hardware experiments using a Franka robot in a setup inspired by the Amazon stowing task.
-
 Gradient-Based Trajectory Optimization With Learned DynamicsBhavya Sukhija, Nathanael Köhler, Miguel Zamora, Simon Zimmermann, and 3 more authorsIn 2023 IEEE International Conference on Robotics and Automation (ICRA), 2023
Gradient-Based Trajectory Optimization With Learned DynamicsBhavya Sukhija, Nathanael Köhler, Miguel Zamora, Simon Zimmermann, and 3 more authorsIn 2023 IEEE International Conference on Robotics and Automation (ICRA), 2023Trajectory optimization methods have achieved an exceptional level of performance on real-world robots in recent years. These methods heavily rely on accurate analytical models of the dynamics, yet some aspects of the physical world can only be captured to a limited extent. An alternative approach is to leverage machine learning techniques to learn a differentiable dynamics model of the system from data. In this work, we use trajectory optimization and model learning for performing highly dynamic and complex tasks with robotic systems in absence of accurate analytical models of the dynamics. We show that a neural network can model highly nonlinear behaviors accurately for large time horizons, from data collected in only 25 minutes of interactions on two distinct robots: (i) the Boston Dynamics Spot and an (ii) RC car. Furthermore, we use the gradients of the neural network to perform gradient-based trajectory optimization. In our hardware experiments, we demonstrate that our learned model can represent complex dynamics for both the Spot and Radio-controlled (RC) car, and gives good performance in combination with trajectory optimization methods.
2022
2022
-
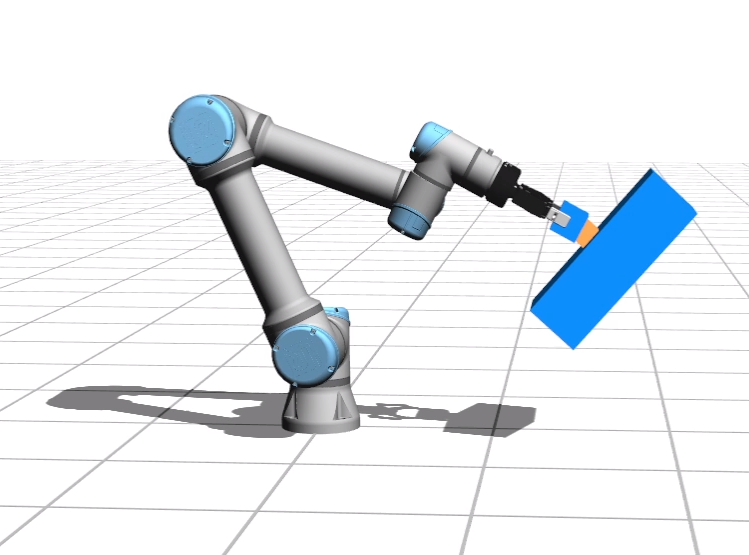 Learning Solution Manifolds for Control Problems via Energy MinimizationMiguel Zamora, Roi Poranne, and Stelian CorosIEEE Robotics and Automation Letters, 2022
Learning Solution Manifolds for Control Problems via Energy MinimizationMiguel Zamora, Roi Poranne, and Stelian CorosIEEE Robotics and Automation Letters, 2022A variety of control tasks such as inverse kinematics (IK), trajectory optimization (TO), and model predictive control (MPC) are commonly formulated as energy minimization problems. Numerical solutions to such problems are well-established. However, these are often too slow to be used directly in real-time applications. The alternative is to learn solution manifolds for control problems in an offline stage. Although this distillation process can be trivially formulated as a behavioral cloning (BC) problem, our experiments highlight a number of significant shortcomings arising due to incompatible local minima, interpolation artifacts, and insufficient coverage of the state space. In this paper, we propose an alternative to BC that is efficient and numerically robust. We formulate the learning of solution manifolds as a minimization of the energy terms of a control objective integrated over the space of problems of interest. We minimize this energy integral with a novel method that combines Monte Carlo-inspired adaptive sampling strategies with the derivatives used to solve individual instances of the control task. We evaluate the performance of our formulation on a series of robotic control problems of increasing complexity, and we highlight its benefits through comparisons against traditional methods such as behavioral cloning and Dataset aggregation (Dagger).
2021
2021
-
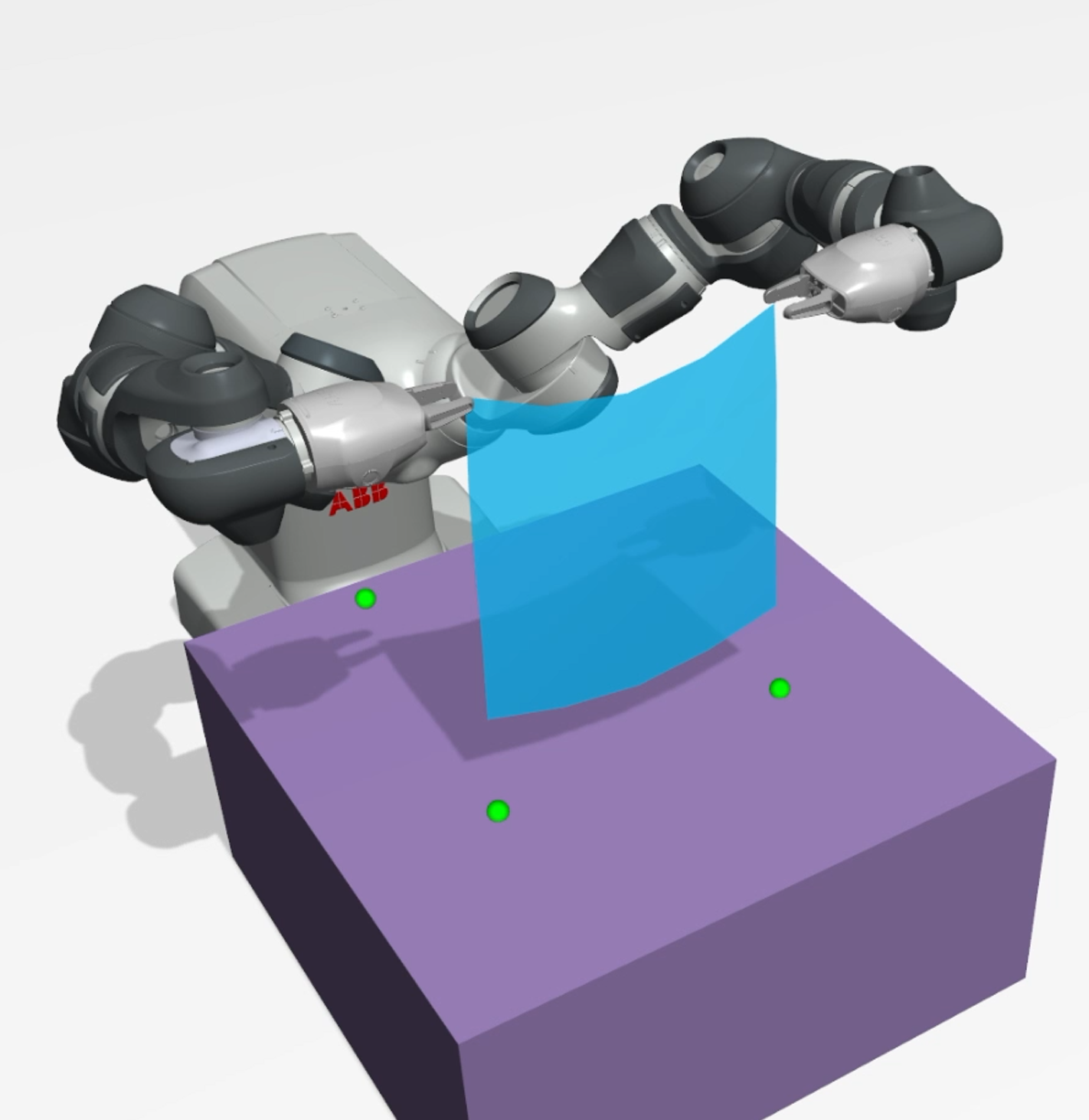 PODS: Policy Optimization via Differentiable SimulationMiguel Zamora, Momchil Peychev, Sehoon Ha, Martin Vechev, and 1 more authorProceedings of the 38th International Conference on Machine Learning, (ICML) , 2021
PODS: Policy Optimization via Differentiable SimulationMiguel Zamora, Momchil Peychev, Sehoon Ha, Martin Vechev, and 1 more authorProceedings of the 38th International Conference on Machine Learning, (ICML) , 2021Current reinforcement learning (RL) methods use simulation models as simple black-box oracles. In this paper, with the goal of improving the performance exhibited by RL algorithms, we explore a systematic way of leveraging the additional information provided by an emerging class of differentiable simulators. Building on concepts established by Deterministic Policy Gradients (DPG) methods, the neural network policies learned with our approach represent deterministic actions. In a departure from standard methodologies, however, learning these policies does not hinge on approximations of the value function that must be learned concurrently in an actor-critic fashion. Instead, we exploit differentiable simulators to directly compute the analytic gradient of a policy’s value function with respect to the actions it outputs. This, in turn, allows us to efficiently perform locally optimal policy improvement iterations. Compared against other state-of-the-art RL methods, we show that with minimal hyper-parameter tuning our approach consistently leads to better asymptotic behavior across a set of payload manipulation tasks that demand a high degree of accuracy and precision.
2020
2020
-
 A Multi-Level Optimization Framework for Simultaneous Grasping and Motion PlanningSimon Zimmermann, Ghazal Hakimifard, Miguel Zamora, Roi Poranne, and 1 more authorIEEE Robotics and Automation Letters, 2020
A Multi-Level Optimization Framework for Simultaneous Grasping and Motion PlanningSimon Zimmermann, Ghazal Hakimifard, Miguel Zamora, Roi Poranne, and 1 more authorIEEE Robotics and Automation Letters, 2020We present an optimization framework for grasp and motion planning in the context of robotic assembly. Typically, grasping locations are provided by higher level planners or as input parameters. In contrast, our mathematical model simultaneously optimizes motion trajectories, grasping locations, and other parameters such as the pose of an object during handover operations. The input to our framework consists of a set of objects placed in a known configuration, their target locations, and relative timing information describing when objects need to be picked up, optionally handed over, and dropped off. To allow robots to reason about the way in which grasping locations govern optimal motions, we formulate the problem using a multi-level optimization scheme: the top level optimizes grasping locations; the mid-layer level computes the configurations of the robot for pick, drop and handover states; and the bottom level computes optimal, collision-free motions. We leverage sensitivity analysis to compute derivatives analytically (how do grasping parameters affect IK solutions, and how these, in turn, affect motion trajectories etc.), and devise an efficient numerical solver to generate solutions to the resulting optimization problem. We demonstrate the efficacy of our approach on a variety of assembly and handover tasks performed by a dual-armed robot with parallel grippers.